Reinforcement Learning is Going Mainstream – DeepSeek Shows How
Given the world is all raving about DeepSeek , I usually take excruciating amount of time to study something and make a practice to be thorough in it. As a result, I usually fail to keep up with the trends in tech field.
However, DeepSeek model was too compelling for me to pick much interest in this new AI-marvel.
What Fascinates Me About DeepSeek?
What fascinates me is its underlying architecture and workings
DeepSeekMath , powered by advanced reinforcement learning principles, pushes the boundaries of mathematical reasoning.
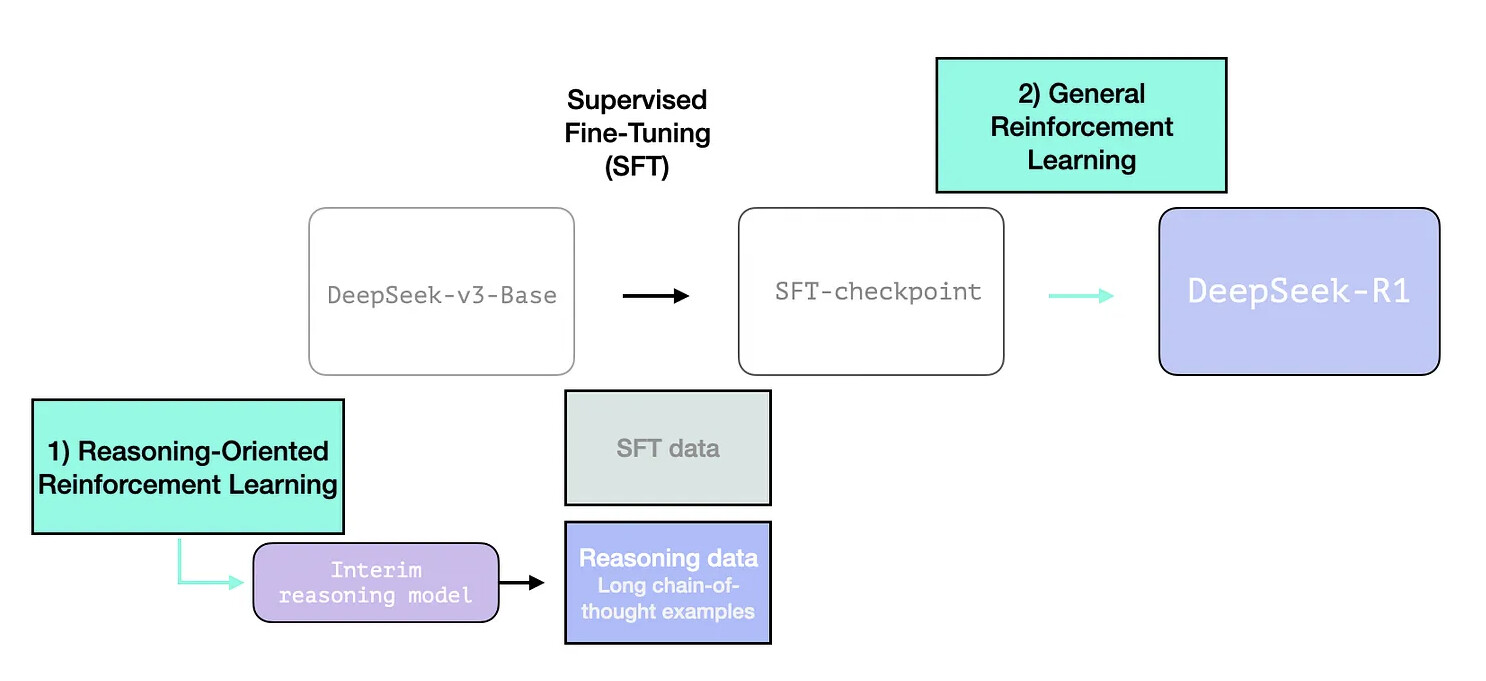
The crux of training relies on reinforcement learning, which focuses on maximizing rewards through policy optimization. It goes beyond current industry that heavily relies on supervised fine-tuning (SFT) by showing that reinforcement learning (RL) can improve reasoning capabilities. There is also CoT based examples that improve the reasoning ability of large language models in arithmetic, commonsense, and symbolic reasoning tasks (through an intermediate reasoning model). But if we only rely on reasoning enhancements, the model will fail to give good results in non-reasoning tasks, thus, we add another step of training to achieve generalization capabilities. I will not cover much on CoT right now as this isn’t in the scope of this article. Nevertheless, below is the diagram for reference.
What is a Policy in RL?
A policy can be thought of as a strategy for selecting an action. In practice, it’s a probability
distribution assigned to the set of actions. Highly rewarding actions will have a high probability and vice versa. If an action has a low probability, it doesn’t mean it won’t be picked at all. It’s just less likely to be picked.
The process of policy optimization iterates through two phases until the convergence:
- Policy evaluation:
Policy evaluation takes a policy as input and computes the expected value of each state under that policy. This is done by recursively calculating the expected value of each state, taking into account the transition probabilities and rewards of the MDP (Markov Decision Process)
- Policy improvement:
Policy improvement takes the value function as input and computes a new policy that is most likely expected to be at least as good as the old policy. This is done by choosing the action in each state that leads to the highest expected value.
In real-world RL scenarios, exact evaluation and improvement are computationally infeasible, so models rely on approximations, such as Proximal Policy Optimization (PPO).
DeepSeekMath and Group Relative Policy Optimization (GRPO)
DeepSeekMath is the highlight of the model because it uses Group Relative Policy Optimization (GRPO), a much better version of PPO.
Traditional Proximal Policy Optimization PPO focuses on policy updates based on absolute
performance improvements, whereas GRPO emphasizes relative performance within a group.
Below is an attempt to simplify the GRPO workings:
This explanation is breaking down Group Relative Policy Optimization (GRPO) and how it updates the policy in reinforcement learning. Let’s go through each step and then focus on why KL
divergence is used in the last part.
Step 1: Group Sampling
- For each prompt, the model generates G = 16 responses.
- These responses are considered a group , meaning they are treated together for calculating
rewards and advantages. - This technique helps in stabilizing updates by considering multiple variations instead of
relying on just one outcome.
Step 2: Reward Normalization
- Each response is assigned a reward based on accuracy, formatting, and language consistency.

Why normalize? Normalization stabilizes training by ensuring rewards aren’t too extreme and
reducing the variance of group responses.
Step 3: Policy Update
- This part updates the policy to maximize advantage while keeping it from deviating too
much. - The update follows:
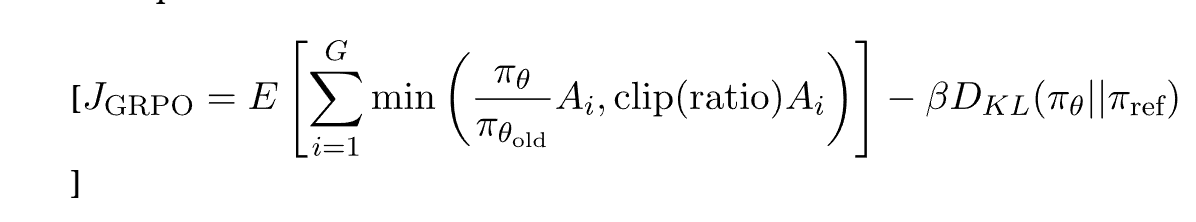
Why KL Divergence?
-
KL divergence measures how different two probability distributions are.
-
The below formula ensures that the new policy does not deviate too far from the previous one.
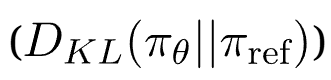
-
The term ( β = 0.01 ) controls how strongly this constraint is applied.
Breaking Down the Equation
1. The First Term: Policy Improvement
o 𝛑𝛉/𝛑𝛉 old represents how much the new policy is different from the old one.
o The min function ensures that updates are controlled (like in PPO) to prevent drastic
policy shifts.
o This part maximizes advantage while making sure updates are not too extreme.
2. The Second Term: KL Constraint
o The KL penalty keeps the policy from changing too aggressively.
o Without this term, the policy might take huge updates and become unstable.
o The value ( β= 0.01 ) is a regularization factor that prevents excessive divergence.
Why Is KL Important?
- If the new policy changes too much from the old one, it can lead to instability in training.
- KL divergence acts as a regularization term , ensuring gradual updates.
- This approach balances exploration (new updates) and stability (staying close to the old
policy).
This approach during model optimizations causes to drastically reduce memory usage, which is a huge advantage for training LLMs.
It is combined with major high-quality mathematical content for training.
Why Emphasis on Reinforcement Learning?
This is not just for understanding DeepSeek model. RL is also backbone of all the future Robotics works. RL was not a mainstream focus in AI research and applications for a long time.
Mainstream RL usage was most publicized in Gaming Industry. Next most popular domains were operations research, industrial control systems, and algorithmic trading. Other industries like Industrial Robots, Humanoid Robots like Optimus are still at the horizon where they do have potential to seep into common peoples lifestyle. From what I see, the only RL I experience in day-to-day life is through LLM-based chats, which include RLHF.
For years, RL was mainly associated with academic research and gaming challenges, such as beating human players in Go or Dota 2. Its potential for practical applications in industries like robotics, healthcare, and finance wasn’t fully realized until breakthroughs like AlphaGo demonstrated its power.
Nevertheless, after AI saturates the Software Industry, AI with RL will start making series of
breakthroughs that will change the humankind.
This makes me wonder, should we start uncovering ignored or lost algorithms for better innovation?
As the field of AI evolves, combining foundational ideas with fresh perspectives could unlock the next wave of transformative technologies.
References:
→ DeepSeek-R1 : internals made easy ![]() - DEV Community
- DEV Community
→ https://arxiv.org/pdf/2402.
→ https://arxiv.org/html/2405.14804v