Abstract:
Compilers are workhorses of performance behind all AI algorithms. Making algorithms work effectively on GPUs is especially hard - called kernel programming. Compiler ecosystem around GPUs is especially messed up. Compilers are supposed to allow for performance portability of different hardwares but this is usually not the case.
Introduction
I am designing a compiler framework called llama.lisp. As you can tell from the name, the framework is highly inspired by Lisp. Limitations of LLVM are examined critically to improve the framework. A multi layered approach is adopted to tame the complexity of writing such an compiler. No single language is chosen as implementation language to allow for the right tools can be used for right problem. A message oriented architecture is used for foreign function interfacing instead of traditional C based API.
An approach to backend has been the hardest to figure out. Stacks are not clear and codes are hard to read. I value ability to understand something in fewer lines of code over something that is super complex. LLVM has become too complex. This sentiment is now common among the community too:

Besides LLVM doesn’t do the job for GPUs. Both the host and device emitted by LLVM is not backend agnostic. But that is the main selling point of LLVM for CPU frontends. See below for an illustration of the issue:
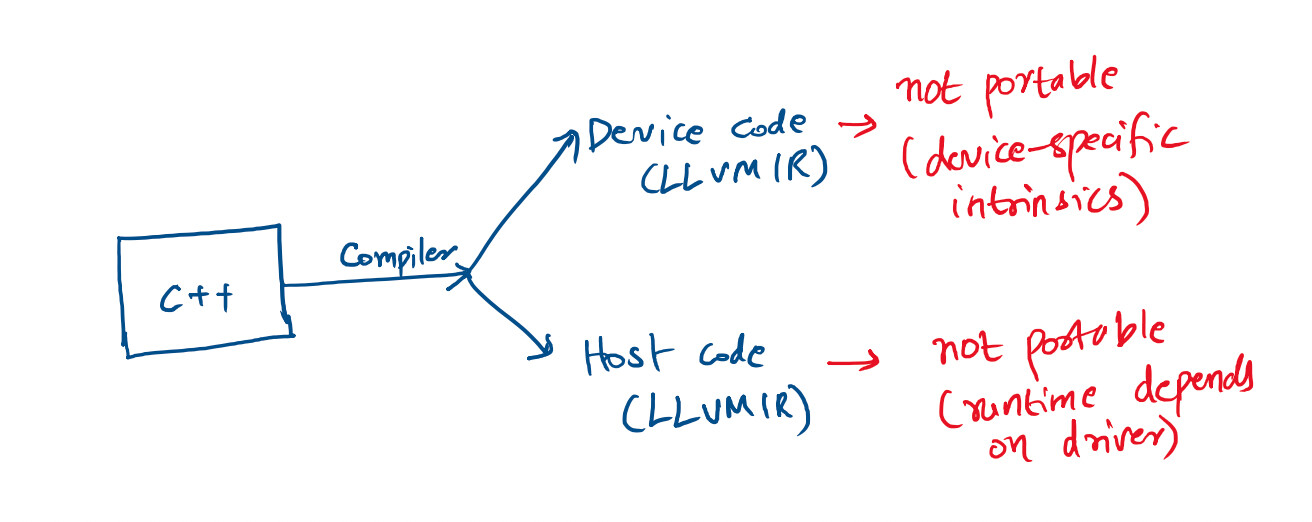
Nevertheless, writing a backend from scratch for PTX, HSA and SPIR-V is not a small project and I don’t intend to take that path now. It’s better to bootstrap from LLVM by creating an IR that abstracts out the intrinsics and runtime.
BRIL/JSON
For the layer above LLVM I plan to use a JSON based IR called BRIL. I have considered my options for this IR and I feel BRIL might be the right fit for me for the following reasons:
- JSON or XML is amazing because I can interface it with any language. Any language can be used for implementation instead of just C/C++.
- SSA is painful to represent in such a text/human readable format. If I have to give up on one of readability or SSA, I will give up on SSA and accept three address code (TAC).
- Hackability and getting started is more important than ‘production’ grade. Educational material helps people get started easily.
This is how this json looks like:
{
"functions": [
{
"name": "add5",
"args": [{"name": "n", "type": "int"}],
"type": "int",
"instrs": [
{ "op": "const", "type": "int", "dest": "five", "value": 5 },
{ "op": "add", "type": "int", "dest": "sum",
"args": ["n", "five"] },
{ "op": "ret", "args": ["sum"] }
]
},
{
"name": "main",
"args": [],
"instrs": [
{ "op": "const", "type": "int", "dest": "a", "value": 9 },
{ "op": "call", "type": "int", "dest": "b",
"funcs": ["add5"], "args": ["a"] },
{ "op": "print", "args": ["b"] }
]
}
]
}
As you can see this is basically LLVM without SSA. Best part about JSON is that I can just emit it from any language and have any language parse it and transform it. So I can use any tool I want. It’s very well documented and a great course is available online to learn more about compilers: CS 6120

Pass Around Programs, not Commands
One of the issues I have is tight coupling between different components of the program. I will not be not very happy if I have to use the same programming language for all my problems. Different problems require different languages because of the ecosystems around it. But the reason the projects usually require mono language is because they pass around commands. Instead I plan to pass around programs.
Let me illustrate. Suppose I have a program that generates BRIL json in Guile scheme like this:
$ guile dsl.scm
{"functions":[{"name":"add5","type":"int","args":[{"name":"n","type":"int"}],"instrs":[{"op":"const","type":"int","dest":"five","value":5},{"op":"add","type":"int","dest":"sum","args":["n","five"]},{"op":"ret","args":["sum"]}]},{"name":"main","type":"int","args":[],"instrs":[{"op":"const","type":"int","dest":"a","value":9},{"op":"call","type":"int","dest":"b","funcs":["add5"],"args":["a"]},{"op":"ret","args":["b"]}]}]}
Now I want to convert this to LLVM IR. Standard approach is to pass the data inside guile to another function. But I am not happy with such an approach because guile doesn’t have great LLVM bindings. Python has an amazing library called llvmlite that generates textual representation of LLVM. So how do I use it?
$ guile dsl.scm | python llvm.py
; ModuleID = ""
target triple = "unknown-unknown-unknown"
target datalayout = ""
define i32 @"add5"(i32 %"n")
{
entry:
%"sum" = add i32 %"n", 5
ret i32 %"sum"
}
define i32 @"main"()
{
entry:
%"b" = call i32 @"add5"(i32 9)
ret i32 %"b"
}
Thus by passing around messages and not commands, I can use any language that suits my purpose. I just need to send programs/messages instead of commands.
Layers of languages
Create hierarchy of abstractions that layer on top of each other in languages, not commands. One language should generate code in another language. This way we can progressively move higher and higher level of abstractions. This is not too different from layers idea in neural network. Each layer in this analogy is a transformer of languages.
For example here’s my DSL that’s above BRIL:
(bril-define ((add5 int) (n int))
(set (five int) (const 5))
(set (sum int) (add n five))
(ret sum))
(bril-define ((main int))
(set (a int) (const 9))
(set (b int) (call add5 a))
(ret b))
This is transformed to BRIL json
{
"functions": [
{
"name": "add5",
"args": [{"name": "n", "type": "int"}],
"type": "int",
"instrs": [
{ "op": "const", "type": "int", "dest": "five", "value": 5 },
{ "op": "add", "type": "int", "dest": "sum",
"args": ["n", "five"] },
{ "op": "ret", "args": ["sum"] }
]
},
{
"name": "main",
"type": "int",
"args": [],
"instrs": [
{ "op": "const", "type": "int", "dest": "a", "value": 9 },
{ "op": "call", "type": "int", "dest": "b",
"funcs": ["add5"], "args": ["a"] },
{ "op": "ret", "args": ["b"] }
]
}
]
}
Which is then transformed into LLVM IR:
; ModuleID = ""
target triple = "unknown-unknown-unknown"
target datalayout = ""
define i32 @"add5"(i32 %"n")
{
entry:
%"sum" = add i32 %"n", 5
ret i32 %"sum"
}
define i32 @"main"()
{
entry:
%"b" = call i32 @"add5"(i32 9)
ret i32 %"b"
}
Which is converted to x86 assembly using llc:
.text
.file "x.ll"
.globl add5 # -- Begin function add5
.p2align 4, 0x90
.type add5,@function
add5: # @add5
.cfi_startproc
# %bb.0: # %entry
movl 4(%esp), %eax
addl $5, %eax
retl
.Lfunc_end0:
.size add5, .Lfunc_end0-add5
.cfi_endproc
# -- End function
.globl main # -- Begin function main
.p2align 4, 0x90
.type main,@function
main: # @main
.cfi_startproc
# %bb.0: # %entry
pushl $9
.cfi_adjust_cfa_offset 4
calll add5@PLT
addl $4, %esp
.cfi_adjust_cfa_offset -4
retl
.Lfunc_end1:
.size main, .Lfunc_end1-main
.cfi_endproc
# -- End function
.section ".note.GNU-stack","",@progbits
Which can assembled into final library. As you can see program is being translated from one language to another. This is the approach I prefer: building a layer of languages.